
Cloud MonitoringでVMインスタンス上の特定プロセスの停止を検知するアラートポリシーを作成してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
Compute Engine の VMインスタンス上で起動するプロセスを特定し、監視対象プロセスの状態変化を検知するアラートポリシーを作成してみます。
本ブログでは特に、監視対象のメトリクスに紐づくラベルを利用したプロセスの特定について説明します。
VMインスタンスのプロセス監視を行う
Opsエージェントのインストール
VMインスタンスのプロセス監視を行うための準備として、VMインスタンスへのOpsエージェントのインストールが必要となります。
Opsエージェントは VMインスタンスの CPU/メモリ/ディスク/プロセスなどのシステムメトリクスを収集し Cloud Monitoring に送信するモニタリング機能や、システムログやジャーナルログを Cloud Logging に送信するロギング機能を持つエージェントです。
以下ドキュメントを参考に監視対象のVMインスタンスにインストールします。
個々の VM への Ops エージェントのインストール
インストールが完了したら、Opsエージェントのステータスを確認してみます。
[Monitoring] → [ダッシュボード] を選択し、[すべてのダッシュボード] からプリセットされた [VM Instances] をクリックします。
対象VMインスタンスの Opsエージェント のステータスが緑チェックマークであればOKです。
ダッシュボードからプロセスの状態を確認する
Opsエージェントがインストールできたら、VM 上のプロセスをモニタリングする を参照し、Cloud Monitoring のダッシュボード上からVMインスタンス上のプロセスの状態を確認してみます。
先ほどの [VM Instances] から監視対象のVMインスタンスをクリックします。
[VM の詳細] という画面が表示されたら [指標]タブから [プロセス] を選択すると、起動中プロセスの様々なメトリクスが確認できます。
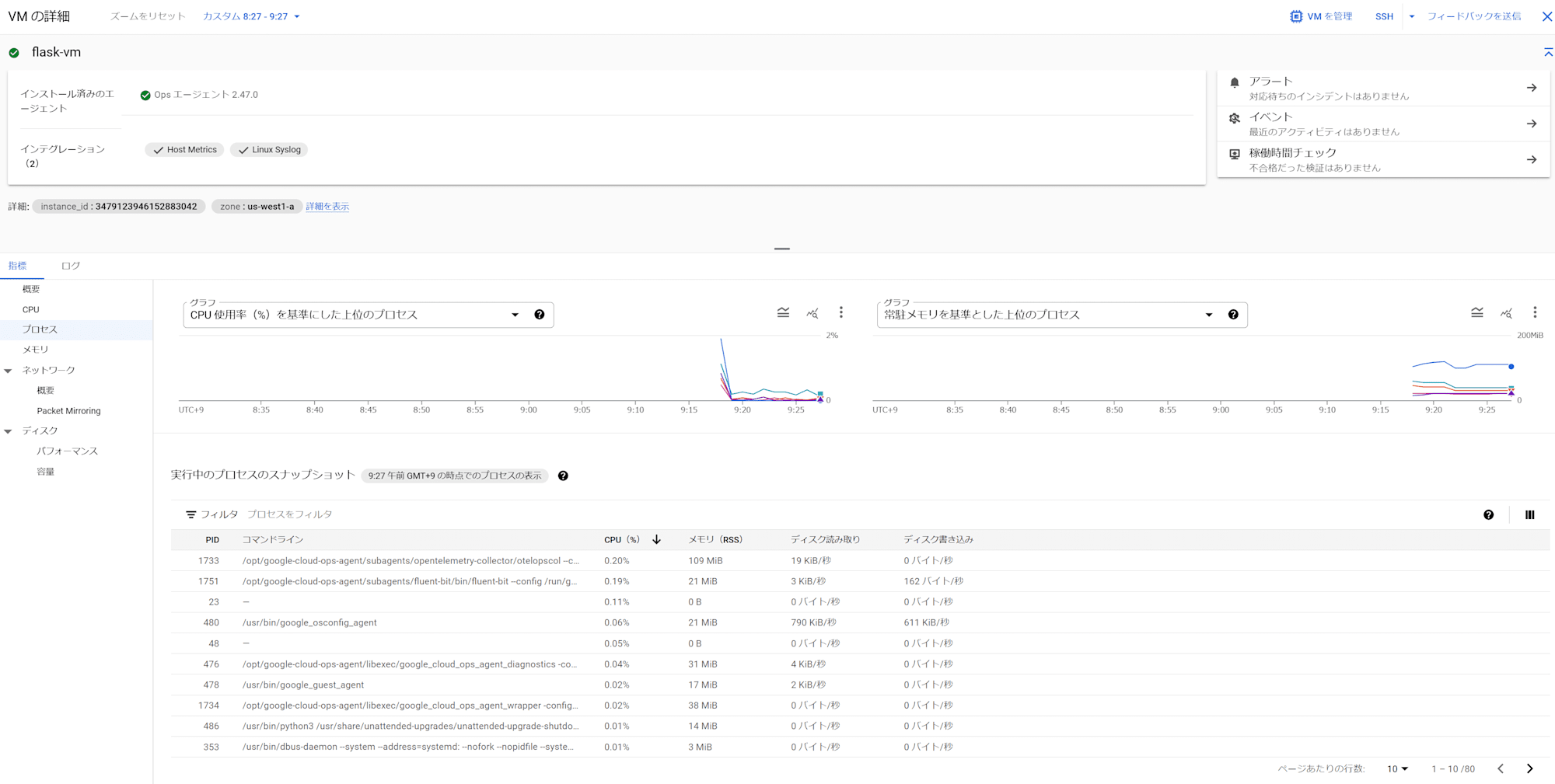
特定のプロセスの停止を検知する
起動中プロセスをダッシュボードから確認する方法はわかりました。では、特定のプロセスを常時監視し、特定のプロセスが停止した際やCPU使用率/メモリ使用量がしきい値を超えた際に通知を行うような仕組みはどのように構成すればよいでしょうか。
ここでは非常に簡単な手順として「ある特定のプロセスからメトリクスを収集できなくなったら(停止したら)アラートを通知する」というアラートポリシーの作成を通じて、対象のプロセスを特定してアラートポリシーを設定する方法を説明します。
プロセスを特定する方法
まずはプロセスを特定する方法を確認します。
プロセスに関するメトリクス(プロセス指標)はagent.googleapis.com/processesから取得できます。
プロセス指標にはCPU時間を表すcpu_time、常駐メモリ使用量を表すrss_usageといったメトリクスがあり、各メトリクスに紐づくラベルと呼ばれる情報によってプロセスを特定することができます。
プロセス指標の種類とラベルについては以下をご参照ください。
プロセス指標
ラベルとは、Cloud Monitoring で収集するリソースやメトリクスに定義された、詳細な分析のために使用できる Key-Value ペアのことです。
前述のドキュメントに記載のある通り、cpu_timeにはcommand_lineやpidといったラベルがあることがわかります。このラベルを指定することでプロセスの特定をしていきます。

特定のプロセスの停止を検知するアラートポリシー
ここでは以下の条件で「ある特定のプロセスからメトリクスを収集できなくなったら(停止したら)アラートを通知する」というアラートポリシーを作ってみます。
command_lineを使い、プロセス名のフルパスによって監視するプロセスを特定- プロセス名のフルパスに文字列
nginxが含まれるプロセスを特定 - 指標なしのアラートポリシーを利用して、メトリクスが収集できなくなったら = プロセスの停止をトリガーとして通知するポリシーを作成します。
- クエリは MQL を使って作成
まずはアラートポリシーの作成を行います。Cloud Console より [Monitoring] → [アラート] → [+CREATE POLICY] をクリックします。
[Policy configuration mode] を [Code editor(MQL or PrompQL)] にします。
[Query editor] に以下を貼り付けします。
fetch gce_instance # Compute Engineインスタンスリソース
| metric 'agent.googleapis.com/processes/cpu_time' # プロセス指標を指定
| filter (metric.command_line =~ '.*nginx.*') # プロセスの特定
| align rate(1m)
| every 1m
| absent_for 1m # 指標なしのアラートポリシー
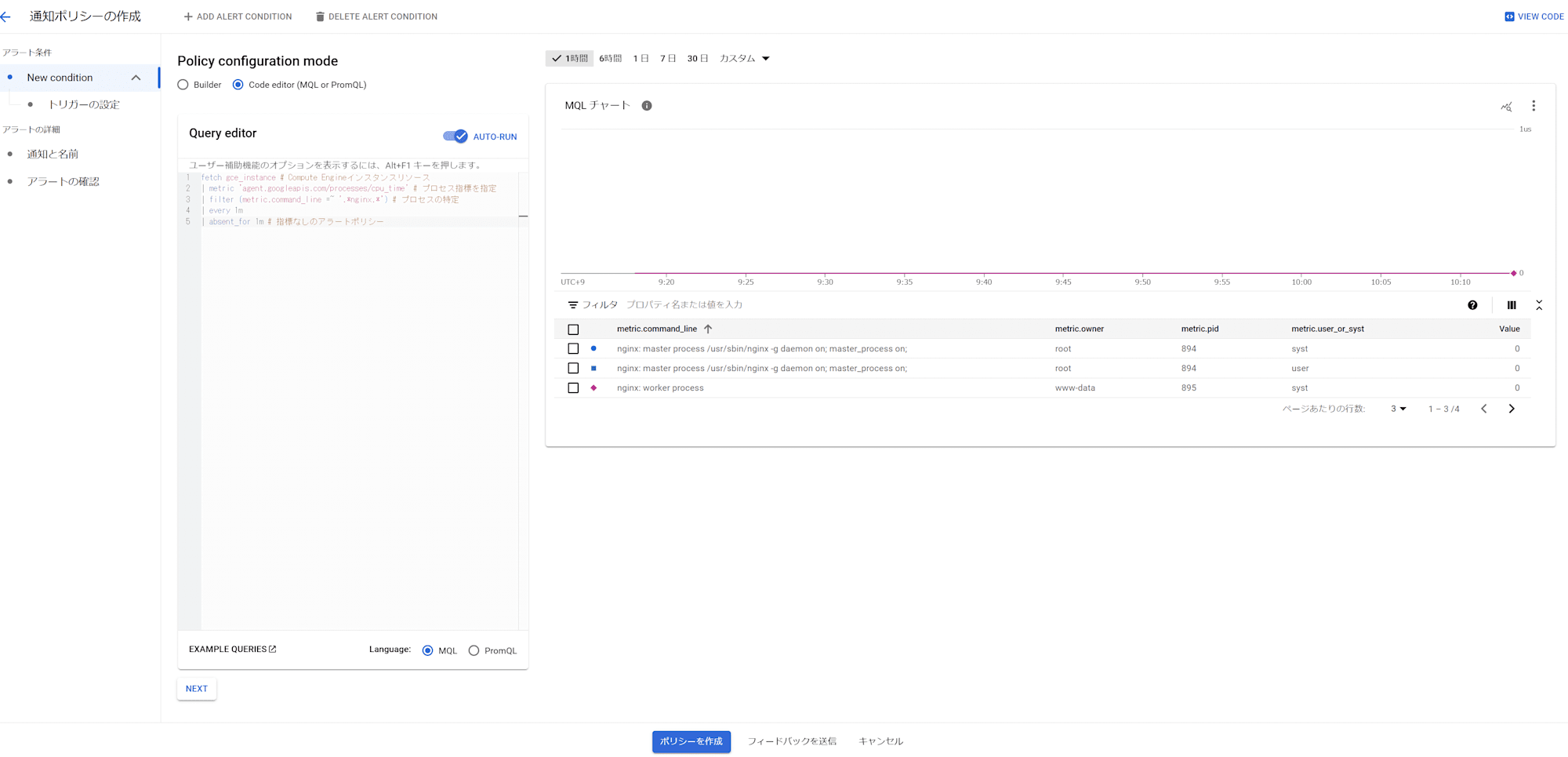
absent_for 1m は1分指標が取得できない場合に通知を行います。
ウインドウ左のツリーより[通知と名前]を選択し以下を設定します。
- [通知チャンネル] から任意の通知先を指定します(未設定であれば[MANAGE NOTIFICATION CHANNELS]から設定します)。ここではメール通知の設定をしています。
- 一番下の項目にある [Name the alert policy] に任意のアラートポリシー名を設定します。ここでは
Stop NGINXとしました。 - [通知の件名] や [Policy Severity Level] を必要に応じて設定します。
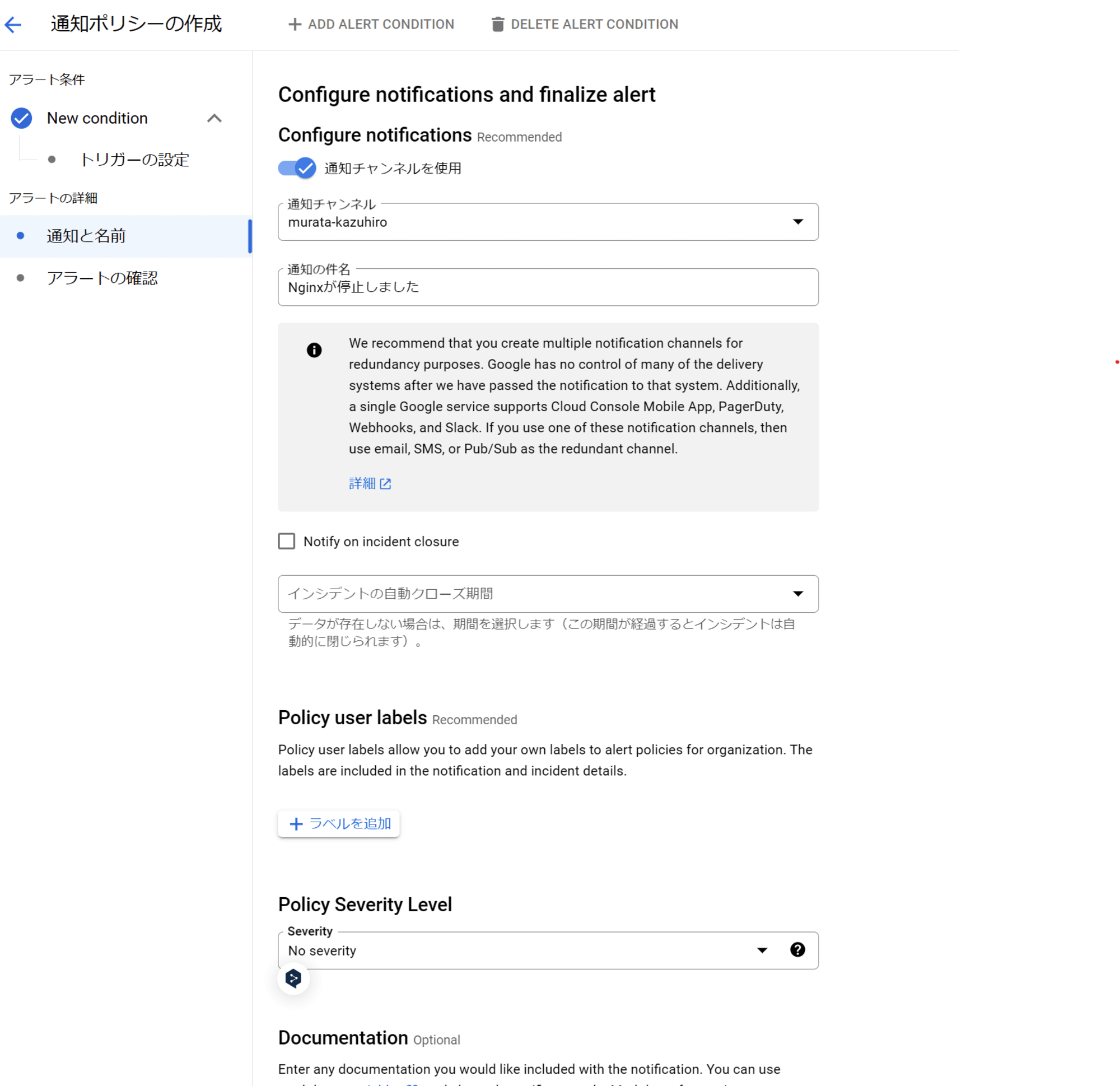
最後に画面下部の [ポリシーを作成] をクリックし完了です。
検証
Compute Engine の VMインスタンスに SSH でログインし、nginxの文字列を含むプロセスを確認します。
$ ps -aux | grep nginx
root 894 0.0 0.2 56380 1560 ? Ss 09:17 0:00 nginx: master process /usr/sbin/nginx -g daemon on; master_process on;
www-data 895 0.0 0.4 56756 2876 ? S 09:17 0:00 nginx: worker process
nginxを停止します。
$ sudo systemctl stop nginx
通知先をメールとしている場合、以下のような形でアラートが発出されます。
![[ALERT - No severity] Nginxが停止しました - murata.kazuhiro@classmethod.jp - Classmethod.jp メール](https://devio2024-media.developers.io/image/upload/v1720748520/2024/07/12/zqf0kqchi3lrwupa6xey.png)
おわりに
Cloud Monitoring から特定プロセスのメトリクスを収集し、アラートポリシーを設定する方法を試してみました。
リソースやメトリクスに紐づくラベルの指定によって、プロセスの特定のような柔軟なモニタリング設定を実現できます。ここでは簡易的な指標なしポリシーを試してみましたが、たとえばcpu_timeを利用してCPU使用率を計算し、閾値超過時のアラート通知を設定するといったことも可能となりますので、ぜひ色々試していただければと思います。










